【創科新思維】微軟研發AI聲音模擬器 VALL-E僅需三秒可模擬真人聲音
微軟所說的VALL-E是「神經編解碼器語言模型」,它源自Meta的AI驅動壓縮神經網絡編碼解碼器,從文本輸入和來自目標說話者的短樣本生成音頻。

據報導,Microsoft(微軟)展示了由文本到語音AI(人工智能)方面的最新研究,微軟聲稱其模型名為VALL-E,該模型僅需三秒鐘的音頻樣本即可模擬某人的聲音。演講不僅可以匹配說話者的音色,還可以匹配其情緒基調,甚至聲學效果等等。VALL-E可能有一天會被用於定製或高端文本到語音的應用程序,儘管它像deepfakes一樣存在被濫用的風險。
微軟所說的VALL-E是「神經編解碼器語言模型」,它源自Meta的AI驅動壓縮神經網絡編碼解碼器,從文本輸入和來自目標說話者的短樣本生成音頻。
研究人員在一篇論文中,描述了他們如何在Meta的LibriLight音頻庫中使用來自7千多名演講者的6萬小時英語演講來訓練VALL-E,而VALL-E試圖模仿的聲音必須與訓練數據中的聲音非常匹配。在這種情況下,VALL-E會使用訓練數據來推斷目標說話者在說出所需文本輸入時的聲音。
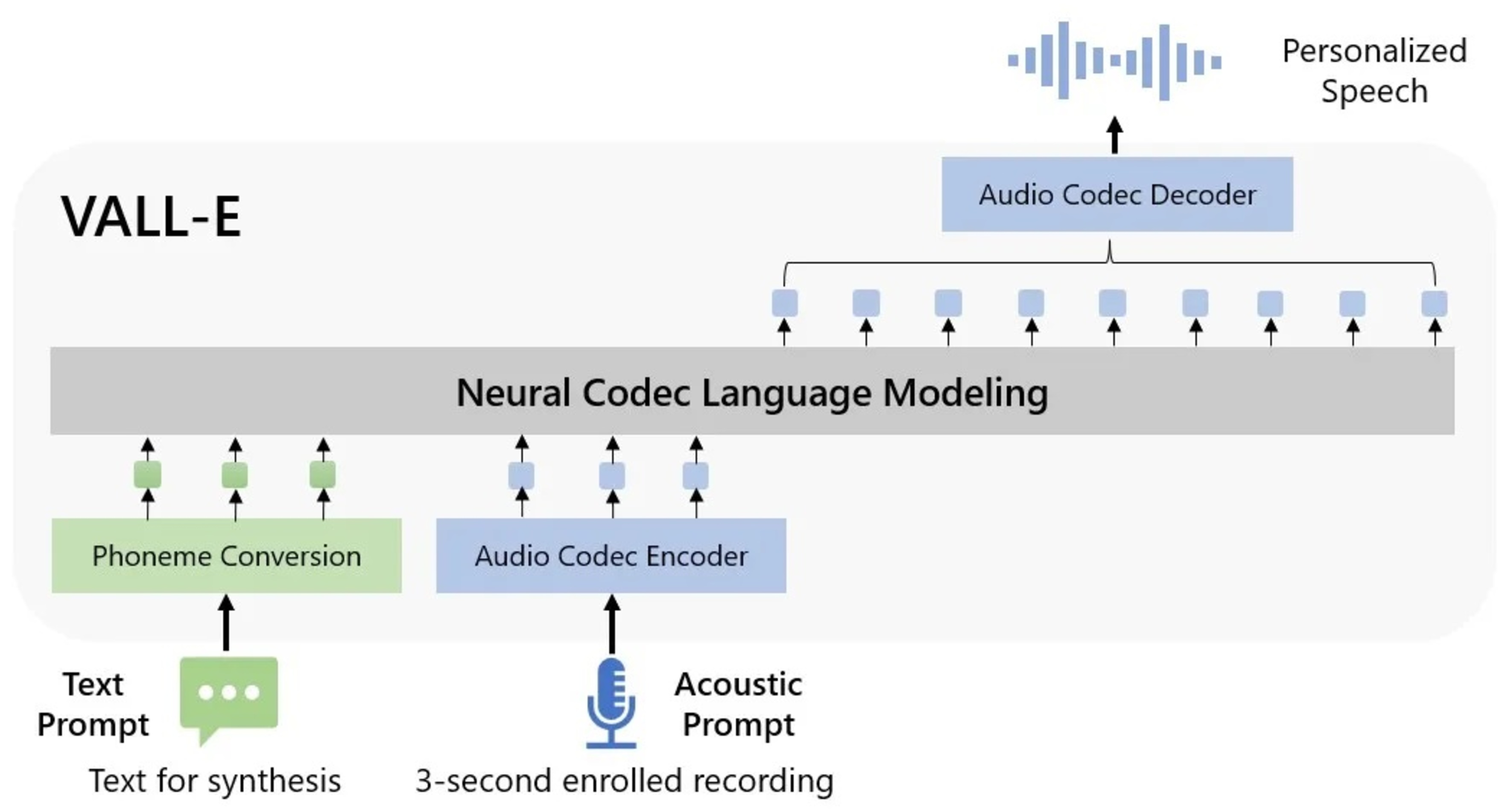
研究團隊在Github頁面上展示VALL-E到底有多好,他們希望人工智能「說話」的每個短語,都會從說話者那裡得到三秒鐘的提示來模仿,團隊並將同一說話者說出另一個短語進行比較,及將傳統的文本到語音轉換合成和最後的 VALL-E樣本。
得出的結果好壞參半,有些聽起來像機器,有些則非常逼真。事實上,它保留了原始樣本的情感基調,這才是有效樣本的賣點。它還忠實地匹配聲學環境,因此如果揚聲器在迴聲大廳中錄製他們的聲音,VALL-E輸出聽起來也像是來自同一個地方。
為了改進VALL-E,微軟計劃擴大其訓練數據,以提高模型在韻律、說話風格和說話人相似性方面的表現,VALL-E還在探索減少不清楚或遺漏單詞的方法。
微軟選擇不將代碼開源,這可能是由於AI固有的風險,可能會把說話塞進別人的嘴裡。微軟補充說VALL-E將在任何進一步的開發中遵循其「微軟人工智能原則」。微軟在其結論的更廣泛的影響部分寫道,由於VALL-E可以合成保持說話者身份的語音,它可能會帶來濫使用的潛在風險,例如欺騙語音識別或冒充他人。
文字:編輯部
熱門文章:

【創科新思維】OpenAI測試ChatGPT付費版本 預計今年的收入為2億美元

【熱點新態勢】騙徒用「變臉」App冒認身份 警方拘捕3男女開假戶口貸款

CoolJobzHRM 人才資源管理軟件

Grow Your Business 能做大你公司生意
立即登記 免費試用 Free Trial for Registration
【重新塑造你未來的工作事業 @ CoolJobz】

Only Knowledge-based & Innovative Careers Prevail in Our Risk Society
Join Us to Make a Difference~
只有知識型及創新工作事業能在風險社會存活
加入我們一起改變吧 ~